
Elasticsearch状态red解决
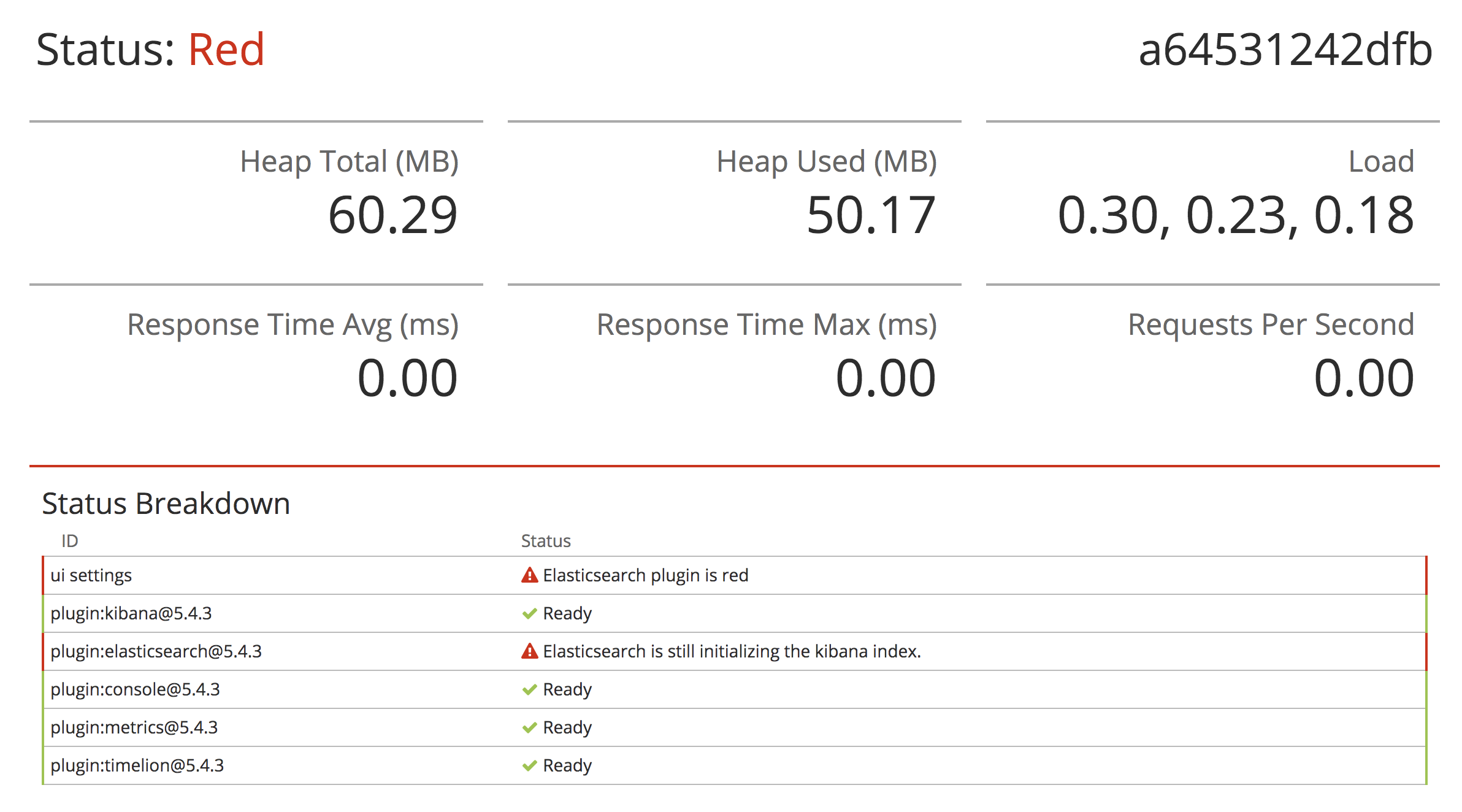
将公司的Elasticsearch的磁盘缩小了一些,节省点成本。但是操作完成后,发现status为red。
参考了相关文章,终于解决了问题。现在将参考文章及解决方法分享如下。
这里说的red,是指es集群的状态,一共有三种,green、red、yellow。具体含义:

问题:ES集群Red
集群节点是否都存在、查看集群状态。
1 | curl -XGET 'http://localhost:9200/_cluster/health?pretty' |
响应
1 | { |
active_shards 是涵盖了所有索引的所有分片的汇总值,其中包括副本分片。
relocating_shards 显示当前正在从一个节点迁往其他节点的分片的数量。通常来说应该是 0,不过在 Elasticsearch 发现集群不太均衡时,该值会上涨。比如说:添加了一个新节点,或者下线了一个节点。
initializing_shards 显示的是刚刚创建的分片的个数。比如,当你刚创建第一个索引,分片都会短暂的处于 initializing 状态,分片不应该长期停留在 initializing 状态。你还可能在节点刚重启的时候看到 initializing 分片:当分片从磁盘上加载后,它们会从 initializing 状态开始。所以这一般是临时状态。
unassigned_shards 是已经在集群状态中存在的分片,但是实际在集群里又找不着。最常见的体现在副本上。比如,我有两个es节点,索引设置分片数量为 10, 3 副本,那么在集群上,由于灾备原则,主分片和其对应副本不能同时在一个节点上,es无法找到其他节点来存放第三个副本的分片,所以就会有 10 个未分配副本分片。如果你的集群是 red 状态,也会长期保有未分配分片(因为缺少主分片)。

1 | curl -XGET "http://localhost:9200/_cat/shards?h=index,shard,prirep,state,unassigned.reason" | grep "UNASSIGNED" |
问题:initializing the kibana index
Elasticsearch is still initializing the kibana index
相关文章 https://stackoverflow.com/questions/31201051/elasticsearch-is-still-initializing-the-kibana-index
解决办法
删除.kibana 索引,但这会导致丢失kibana设置
1 | curl -XDELETE http://localhost:9200/.kibana |
更好的办法如下,不会丢失数据。但我个人测试没有成功
1 | curl -s http://localhost:9200/.kibana/_recovery?pretty |
常见分片未分配原因
| 原因 | 说明 |
|---|---|
| INDEX_CREATED | 由于创建索引的API而未分配 |
| CLUSTER_RECOVERED | 由于集群恢复而未分配 |
| INDEX_REOPENED | 由于索引重新打开而未分配 |
| DANGLING_INDEX_IMPORTED | 由于引入dangling索引而未分配 |
| NEW_INDEX_RESTORED | 由于恢复到新索引而未分配 |
| EXISTING_INDEX_RESTORED | 由于恢复到关闭的索引而未分配 |
| REPLICA_ADDED | 由于显式添加副本而未分配 |
| ALLOCATION_FAILED | 由于分片分配失败而未分配 |
| NODE_LEFT | 由于该分片所在的节点离开集群而未分配 |
| REROUTE_CANCELLED | 由于显式的取消reroute命令而未分配 |
| REINITIALIZED | 由于分片重新初始化而未分配 |
| REALLOCATED_REPLICA | 由于一个更好的副本分片位置被识别到,该副本分片分配取消 |
原文 https://bbs.huaweicloud.com/forum/thread-67634-1-1.html
终结
一、遇到集群Red时,我们可以从如下方法排查:
- 集群层面:/_cluster/health。
- 索引层面:/_cluster/health?pretty&level=indices。
- 分片层面:/_cluster/health?pretty&level=shards。
- 看恢复情况:/_recovery?pretty。
二、有unassigned分片的排查思路
- _cluster/allocation/explain,先诊断。
- /_cluster/reroute尝试重新分配。
三、数据重放
- 如果实在恢复不了,那只能索引重建了。提供一种思路:
先新建备份索引
相关文章
Elasticsearch is still initializing the kibana index
